I'm doing consulting and contract work, but also looking for full time work. If you know anyone who wants to improve their IT efficiency, has security concerns and or is looking for a good IT leader or strong lieutenant please reach out.
This week though I'm helping a long time customer with a NAC and Security assessment. Part of that is helping to customize their Netsight instance to be a bit more useful to them. They are an Extreme customer from the Enterasys days so they have all Enterasys switches, not wireless though.
If you use Oneview, which is the web based interface to Netsight, you have probably seen the dashboards that exist. The NMS dashboard is sort of the main one I used to use. It's a good overview of the health of the network. If you don't use Extreme wireless though the entire middle pane is wasted.
So I wanted to change that to show NAC (or Identity and Access Manager if you like that name better). I figured since I was doing the work, I'd share with you how easy it is to do.
Login to Oneview and go to the administration tab, then click on Report Designer.

Choose the “system reports” you want to change. The main screen is NMS Dashboard but you can also change the Purview or Identity and Access Manager ones as well.
Simply change the Component name to be the data you want to show and then click save.
You can only use existing components but there are quite a few. These are some of the Identity and Access ones.
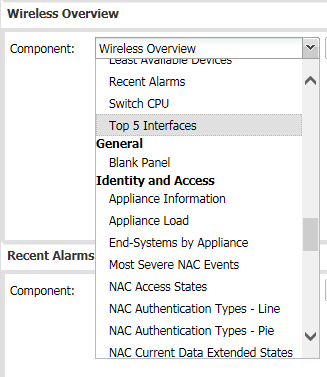
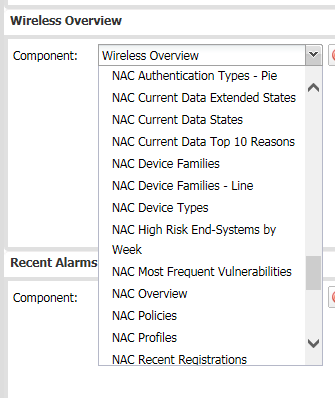
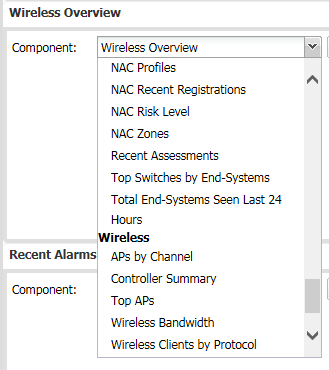
It will bring up the new Dashboard automatically.
If you want to delete it, go into the My Reports at the top. (not the one you originally edited) , highlight the one you want to get rid of and hit the delete icon.
The help files in Netsight are really good about this as well.
Hope it helps!
Hope it helps!